付注1-1 「景気」インデックスの作成方法について
1 テキストデータの取得と学習用データについて
分析対象としたニュース記事の取得については、白川・塩野(2017)を参考に、Google Custom Search APIを利用し取得した。検索語句は「景気」、期間は2017年1月1日から同年11月30日までを指定し、ある程度過去に遡ってデータが取得できた毎日新聞・日本経済新聞・産経新聞の3紙を対象とした。記事については、タイトルと本文を取得しているが、記事の全文取得ができないものに関しては、白川・塩野(2017)と同様、第一パラグラフのみを取得している1。最終的には、月例経済報告に関係する記事を除き、タイトルまたは本文に「景気」という用語を含む計2,129記事を分析対象のデータとした。
学習用テキストデータについては、内閣府「景気ウォッチャー調査」における景気判断理由集(現状)を利用した。テキストデータの期間は2012年~2016年の5年間、総数76,788コメントを使用した。景気の現状判断のコメントのうち、「良くなっている・やや良くなっている」をポジティブ、「変わらない」をニュートラル、「やや悪くなっている・悪くなっている」をネガティブと分類した。
2 機械学習の方法について
以下2種類の機械学習の方法により指数を作成した。
① ナイーブ・ベイズによる学習分類2
ナイーブ・ベイズによる学習分類はベイズの定理を利用した学習分類である。この分類手法はスパムメールの分類など幅広い分野で使用されおり、精度評価のベンチマークとして頻繁に利用されている。学習を実行するに当たってはフリーウェアであるKH Coderを利用した。
手法の概要を説明すると、まずベイズの定理によれば条件付き確率は以下のように表現できる。ここでp(x|y)は,y という条件のもとでx が生じる確率を表す。
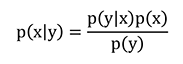
p(x|y)=(p(y|x)p(x))/p(y)
一連の抽出語W を含む文書が,カテゴリC に属する確率p(C|W) を直接計算することは難しいが,上の定理を用いることでp(C|W) は以下のように表すことができる。
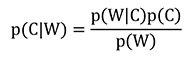
p(C|W)=(p(W|C)p(C))/p(W)
このように変形することで,p(C|W) を推定できるようになる。ナイーブベイズモデルでは、すべてのカテゴリについてこの値を計算し,最大の値をとるカテゴリに当該の文書を分類する。ただし,分母のp(W) はすべてのカテゴリに共通なので無視し、分子のみを計算して各カテゴリのスコアとしている。また、n 種類の語が含まれていた場合のp(W|C) は,以下のように計算している。
p(W|C)=p(w1|C)p(w2|C)p(w3|C)p(w4|C)…p(wn|C)
なお、実際にp(W|C)p(C)を計算するに当たっては、これの自然対数を計算している。これは、アンダーフロー(多数の確率の積を計算すると、非常に小さな値となり、コンピューター上で正しく表現・計算できなくなってしまうこと)を避けるためである。
この学習結果を用いて、分析対象の各ニュース記事をポジティブ、ニュートラル、ネガティブに分類した。その上で、DI =(ポジティブに分類された記事の割合)-(ネガティブに分類された記事の割合)を日次ベースで算出した。
② ニューラルネットワークによる学習分類3
さらに、今回はニューラルネットワークを用いたセンチメント指数を作成した。
この方法を用いるための事前準備として、学習用テキストデータを単語単位の分かち書きに変換した。変換の際には、主要な形態素解析ツールの一つであるMeCabを用い、システム辞書には新語が多数含まれているmecab-ipadic-NEologdを指定した。
学習モデルの作成には、Facebook Artificial Intelligence Research(FAIR)が開発した自然言語ライブラリであるfasttextを利用した。
モデル作成の初めのステップは、テキストに含まれる各単語をベクトルに変換(今回は100次元)することである。ベクトルに変換することで、以下のような単語同士の演算が可能となる。
「王様」-「男」+「女」=「女王」
「パリ」-「フランス」+「日本」=「東京」
次に、学習に用いたニューラルネットワークは3層から構成される。入力層には各テキストに含まれる単語のベクトル、出力層は分類(ポジティブ・ニュートラル・ネガティブのいずれか)として、ネガティブサンプリング法によって学習を行った。なお、その他のパラメーターはデフォルト値を用いた。
この学習結果を用いて、各ニュース記事がポジティブ、ニュートラル、ネガティブそれぞれに分類される確率を計算した。そして、センチメント指数 =(ポジティブに分類される確率×1)+(ニュートラルに分類される確率×0)+(ネガティブに分類される確率×(-1))を日次ベースで算出した。